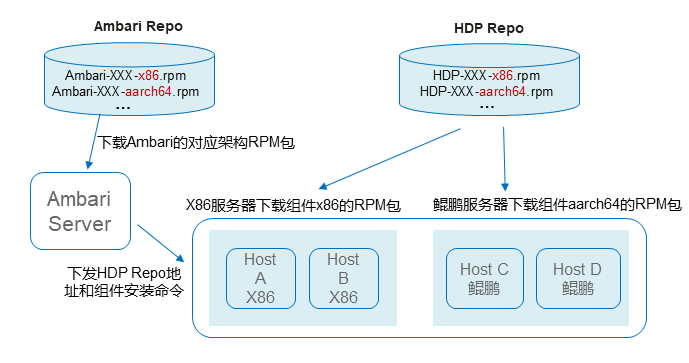
华为鲲鹏计算大数据支持基于HDP开源软件混合部署
.jpg)
.jpg)
.jpg)
.jpg)
华为鲲鹏计算大数据支持基于HDP开源软件混合部署。
适用的组件有:
1. HDFS、Yarn(MR)、Hive、Spark、Flink;
2. Hbase、ElasticSearch、Storm/Kafka/Flume、Solr;
3. 不支持混部的组件:Redis、Hue、Sqoop、Oozie,建议采用鲲鹏或x86独立部署。
部署步骤:
1. 确认OS、JDK等版本满足混部要求;
2. Ambari及所需大数据组件移植为鲲鹏版本;
3. 基于《Ambari移植混部指导书》制作X86版本和鲲鹏版本的软件包,创建YUM源;
4. 通过Ambari页面操作,配置YUM源地址,扩容增加节点。